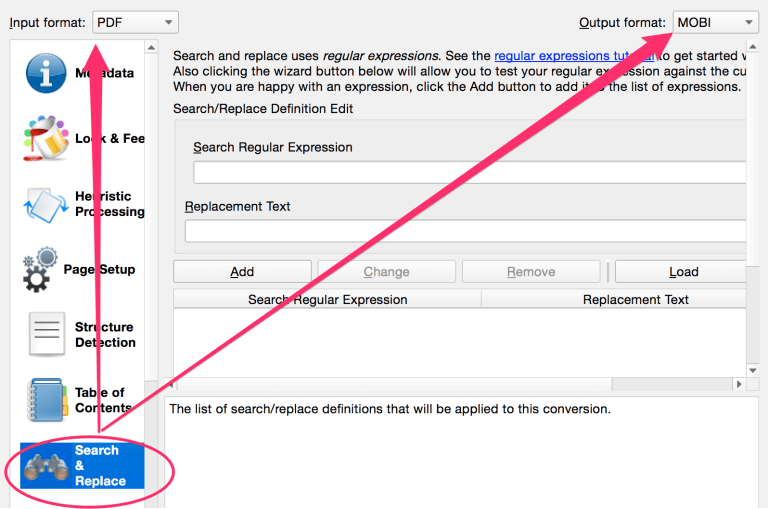
In the following book there was an alternating header with author name and title. Remember, the number and text will often change from page to page.
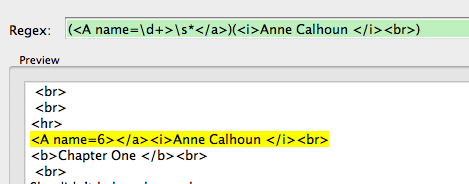
<a name=”6″></a><em>Anne Calhoun </em>
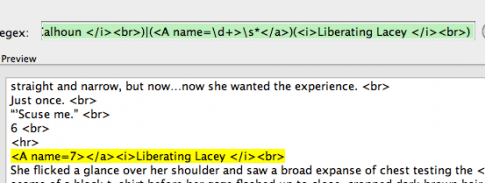
<a name=”7″></a><em>Liberating Lacey </em>
and a footer with the page numbers:
6 <br>
<hr />
Basically I copy any text that needs to be removed and then replace the number with \d+. My reg expression is as follows.
- <a name=”\d+”></a>)(<i>Anne Calhoun </i><br>